Bug #324
BUG: scheduling while atomic: swconfig/1340/0x00000002
Description
In my quest for lower latency throughout the system, I increased the clock interrupt from 100 to 256, enabled low latency desktop, and wanted to see what bugs I would flush out by doing so.This is one… I had put down working on the switch last year, in march, after beating the buffering problem on it, or so I thought. I never got around to seeing if the the wfq algorithm on it could be made to work - the early data sheets had glowingly cool stuff on them, the later ones deleted that info, so it seems likely that much of the QoS system on-chip actually doesn’t work. That said, finding ways to expose more of the switch’s functionality higher up on the stack would be good.
Now, previously, I’d tried for a clock interrupt of 1000, and exposed at least two other bugs elsewhere, this one is new…
[ 21.792968] se00: link up (1000Mbps/Full duplex)
[ 22.691406] ADDRCONF(NETDEV_UP): ge00: link is not ready
[ 26.695312] BUG: scheduling while atomic: swconfig/1340/0x00000002
[ 26.699218] Modules linked in: gpio_buttons usb_storage ohci_hcd xt_hashlimit ip6t_REJECT ip6t_LOG ip6t_rt ip6t_hbh ip6t_mh ip6t_ipv6header ip6t_frag ip6t_eui64 ip6t_ah ip6table_raw ip6_queue ip6table_mangle ip6table_filter ip6_tables nf_conntrack_ipv6 nf_defrag_ipv6 nf_nat_irc nf_conntrack_irc nf_nat_ftp nf_conntrack_ftp xt_HL xt_hl ipt_ECN xt_CLASSIFY xt_time xt_tcpmss xt_statistic xt_mark xt_length ipt_ecn xt_DSCP xt_dscp xt_string xt_layer7 xt_quota xt_pkttype xt_physdev xt_owner ipt_MASQUERADE iptable_nat nf_nat xt_recent xt_helper xt_connmark xt_connbytes pptp xt_conntrack xt_NOTRACK iptable_raw xt_state nf_conntrack_ipv4 nf_defrag_ipv4 nf_conntrack ehci_hcd sd_mod pppoe pppox ipt_REJECT xt_TCPMSS ipt_LOG xt_comment xt_multiport xt_mac xt_limit iptable_mangle iptable_filter ip_tables xt_tcpudp x_tables ip_gre gre ifb sit tunnel4 tun ppp_async ppp_generic slhc vfat fat ext4 jbd2 mbcache autofs4 ath9k ath9k_common ath9k_hw ath nls_utf8 nls_iso8859_2 nls_iso8859_15 nls_iso8859_13 nls_iso8859_1 nls_cp437 mac80211 usbcore scsi_mod nls_base ts_fsm ts_bm ts_kmp crc16 crc_ccitt ipv6 cfg80211 compat arc4 aes_generic crypto_algapi leds_gpio button_hotplug gpio_keys_polled input_polldev input_core
[ 26.804687] Call Trace:
[ 26.808593] [<802b1200>] dump_stack+0x8/0x34
[ 26.812500] [<802b14a8>] __schedule+0x88/0x540
[ 26.816406] [<802b22d4>] schedule_timeout+0x1cc/0x200
[ 26.824218] [<80083f88>] msleep+0x20/0x30
[ 26.828125] [<801ee05c>] rtl8366s_reset_chip+0x2c/0x90
[ 26.832031] [<801ee474>] rtl8366s_sw_reset_switch+0x18/0x74
[ 26.835937] [<801e62fc>] swconfig_set_attr+0x1f4/0x258
[ 26.843750] [<80233f94>] genl_rcv_msg+0x1d4/0x220
[ 26.847656] [<80233304>] netlink_rcv_skb+0x6c/0xe8
[ 26.851562] [<80233db0>] genl_rcv+0x24/0x34
[ 26.855468] [<80232b58>] netlink_unicast+0x274/0x34c
[ 26.863281] [<80232ed4>] netlink_sendmsg+0x2a4/0x334
[ 26.867187] [<801fefd0>] sock_sendmsg+0x84/0xa4
[ 26.871093] [<801ff25c>] __sys_sendmsg+0x1a4/0x24c
[ 26.875000] [<80200af8>] sys_sendmsg+0x48/0x7c
[ 26.878906] [<8006a3a4>] stack_done+0x20/0x40
[ 26.882812]
Attachments
{kind=link}
History
1. Using forced (desktop) preemption causes the above bug. Even if you use a slower clock interval. Interestingly, even though this appears: “BUG: scheduling while atomic: swconfig/1340/0x00000002”, after a minute or so, the ethernet chips start functioning fine (perhaps with a release and renew on the connected clients). The wireless doesn’t appear to be affected.
2. Using config_hz 1000 with server or voluntary preemption, a similar issue occurs were the ethernet switch seems to fail, but I see no immediate error logs in the kernel message. Wireless again appears to be ok.
3. I can build a successful firmware using voluntary preemption and config_hz 250. The router seems stable using voluntary preemption. Perhaps using a custom HZ value (like 500) could be a workaround.
In my case I was hoping for mildly better behavior from QFQ, which I seem to be getting.
build_dir/toolchain-mips_r2_gcc-4.5-linaro_uClibc-0.9.32/linux/arch/arm/include/asm/param.h
But I may be wrong since I think that gets overwritten from source when building the kernel? I also tried to set config_hz_500=y and config_hz=500 in the relevant config files, but I’m not sure if they are sticking. Any help would be appreciated on how to actually change the default.
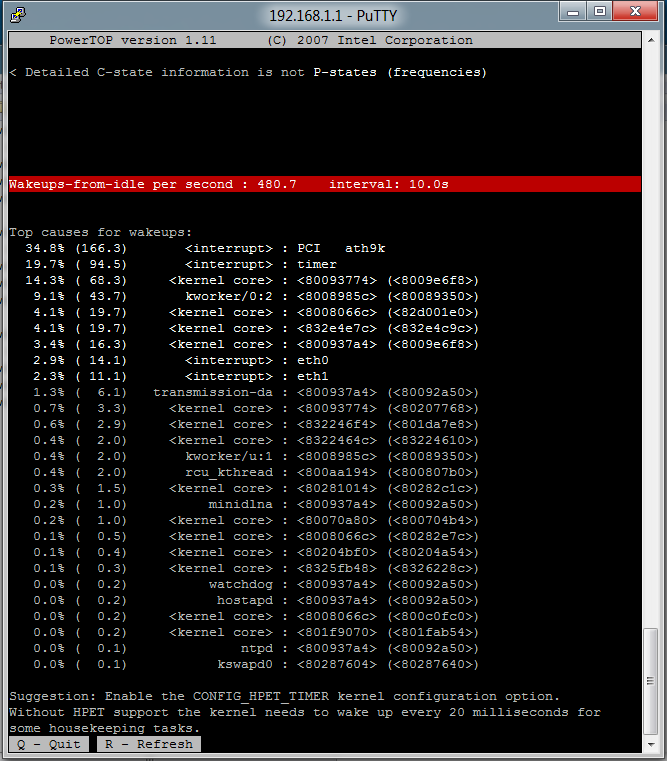
Anyways, enabling kernel timing stats debugging and installing powertop, I see there are about 400 “wakeups-from-idle per second” when doing minor browsing. Ath9k uses about 170 in idle. So I’d argue that we need just around 500Hz just to maintain responsiveness at least on the software side. I’m guessing that the interrupts can go much higher than the defined 500Hz though when required, because it shoots up to 2000-3000 (eth0) when doing a simple Samba transfer.
I’m not sure how the interrupts are related to the HZ or context switching though. It’s probably complicated.
One effect is that Samba transferring a bulk file from the local PC to the attached HDD much faster now, about 16MB/s vs. 12MB/s for the default HZ value. Idle times according to vmstat are also more accurate.
I’m actually just using openwrt trunk, not cerowrt. Is the cerowrt toolchain available for me to build? Then I can test QFQ.
How it affects latency? I’m not sure. Using the default QoS scripts with appropriate limits (txqueuelen, buffers, ECN, timestamps), a Netalyzer test looks the same. But then I’m not using your improved QoS scripts.
Let me know how I can help.
I’m engaged in pushing up the good stuff into openwrt as fast as I can, so others can fiddle with the good stuff (like QFQ) there. I probably won’t be done doing that until after Christmas. (needed-for-me-to-cleanup-and-submit patches are the latest iproute2, and QFQ added to the kernel scheduler packages)
Your results with samba are pretty interesting. My assumption is that the samba daemon is waking up more often than it would otherwise….
Is this samba 3.0 or 3.6? I just pushed samba 3.6.1 into the ceropackages repo (which is largely buildable from normal openwrt, all you have to do is add it to your feeds.conf, and select the package in it)
“default QoS scripts with appropriate limits (txqueuelen, buffers, ECN, timestamps”
I note that almost universally I’m getting better shaping results from very small tx rings - 4 in cerowrt’s case. I also set the openrd (an arm platform) as low as they would go - 20 - and would like to go lower in that case.
Overall I’d take my limited benchmark with a big grain of salt. It would seem it’s limited by the CPU and the scheduler giving the smbd process enough time (also giving the USB interface enough time). I also tried setting the TCP TOS for samba to TCP_CORK since I was doing mainly bulk transfers.
As for my QoS settings; with my slow connection (6000Kbps/1000Kbps), using a txqueuelen of 2 rarely drops packets. I have only a handful of dropped packets over the course of a week. On my Windows 7 clients, the ethernet driver also allows me to set TX and RX buffers to 2. This is pretty good, because I have some other clients that only allow 128 or 256 minimums.
ECN and timestamps are enabled. I don’t see why they aren’t enabled by default in openwrt trunk. I also enabled them on my Windows 7 clients.
I tried applying ethtool -G eth0 rx 16 tx 16, and various other values, on my WNDR3700v2, but it crashes the router immediately. I can set a higher value, rx 64 tx 64, and it doesn’t crash immediately, but eventually (over the course of a few hours).
I seen your ticket about applying ethtool very early in the boot process, so I will try that next. Can you link to the boot file I can edit to apply that?
Anyway, to reduce latency on the driver side:
See the two ethtool lines in:
https://github.com/dtaht/cerofiles/blob/master/files/etc/init.d/boot
This was the only way I was able to reduce the tx ring to sanity was here, before it booted fully.
I’ve gone as low as 2, actually, but that did cut bandwidth (helped on latency, though), and I do hope that BQL will run at 16 to 64 as well or better as things run now at tx 4.
I have been running of late with qfq or sfq, and a longer txqueuelen (150 or so). SFQ and QFQ help a lot on wireless, not so much at gigE speeds, but help a lot at 100Mbit or less (with an uplink)
I have some scripts I’m working on in the deBloat repo that almost work on openwrt as I write.
The lowest I can successfully boot is tx 64 rx 64 for eth0 and eth1. I’m using the latest openwrt trunk. I also tried 32, 8, 2. The defaults are tx 64 rx 128.
Are you only changing the tx value? Perhaps that’s the difference.
TCP_CORK alone has worse performance for bulk transfers than just TCP_NODELAY.
The best combination I found was:
socket options = TCP_NODELAY IPTOS_LOWDELAY TCP_CORK SO_SNDBUF=65536 SO_RCVBUF=65536.
Those options held network utilization at 15.5% on a 1Gbit connection.
Increasing the buffer size allowed me to obtain 18MB/s transfer rates to the attached USB HDD. 32768 sized buffers also worked almost as well.
The lowest I can successfully boot is tx 64 rx 64 for eth0 and eth1. I’m using the latest openwrt >trunk. I also tried 32, 8, 2. The defaults are tx 64 rx 128.
TX rings and RX rings are very different. I usually set TX to 2 or 4 in the early stage boot process (in the /etc/init.d/boot script), and don’t touch the rx ring - which should be about 128…
I do plan to revisit the clock issue at some point tho.
However, on routers with tso/gso/ufo support, and possibly lro/gro, it helps to turn those OFF. The wndr has none of those features, x86s do.
I am running successfully with a 256 clock now.
Cerowrt Project
Recent Updates
Find us elsewhere
#bufferbloat on Twitter
Google+ group
Archived Bufferbloat pages from the Wayback Machine
Sponsors
Comcast Research Innovation FundNlnet Foundation
Shuttleworth Foundation
GoFundMe
Bufferbloat Related Projects
OpenWrt ProjectCongestion Control Blog
Flent Network Test Suite
Sqm-Scripts
The Cake shaper
AQMs in BSD
IETF AQM WG
CeroWrt (where it all started)
Network Performance Related Resources
Jim Gettys' Blog - The chairman of the Fjord
Toke's Blog - Karlstad University's work on bloat
Voip Users Conference - Weekly Videoconference mostly about voip
Candelatech - A wifi testing company that "gets it".